
前言
学习SLAM,《视觉SLAM十四讲》第二版的部分内容及习题的相关笔记。
第1讲 预备知识
内容
SLAM是Simultaneous Localization and Mapping的缩写,即同时定位与地图构建。它是指搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建立环境的模型,同时估计自己的运动。
习题
考虑增广矩阵
,设 为 矩阵,矩阵的秩是指列空间的维数。 - 当
时,方程组无解,可用最小二乘法求近似解。 - 当
时,方程组有唯一解,可以用高斯消元法等求解。 - 当
时,方程组有无穷多解,用特解加 的零空间表示。
- 当
高斯分布即正态分布。
在一维情况下,随机变量
服从正态分布,记作 ,其中 为期望值, 为方差,概率密度函数为 ,当 时,正态分布就成为标准正态分布: 。一维高斯分布如下图所示: 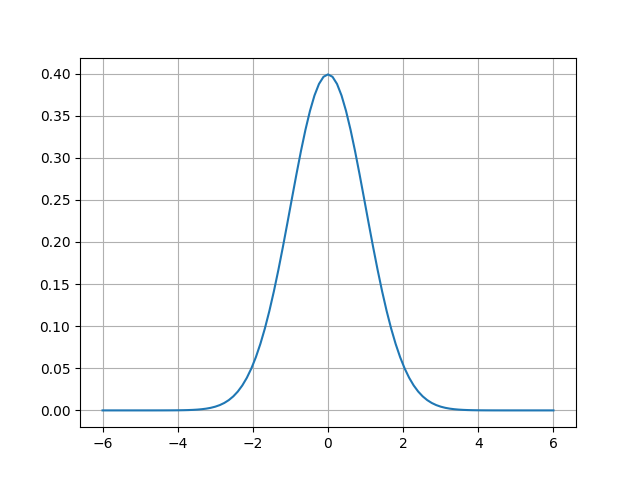
python代码如下:
import numpy as np import matplotlib.pyplot as plt import math def dim1_gaussian_distribution(_x, _mu, _sigma): return np.exp(-1 * ((_x - _mu) ** 2) / (2 * _sigma ** 2)) / math.sqrt(2 * np.pi * _sigma ** 2) def dim1_gaussian_show(_mu=0, _sigma=1): x = np.linspace(_mu - 6 * _sigma, _mu + 6 * _sigma, 101) y = dim1_gaussian_distribution(x, _mu, _sigma) plt.plot(x, y) plt.grid() plt.show() if __name__ == '__main__': print("dim1_gaussian_distribution as main") dim1_gaussian_show()在二维情况下,概率密度函数为
,其中 。二维高斯分布如下图所示: 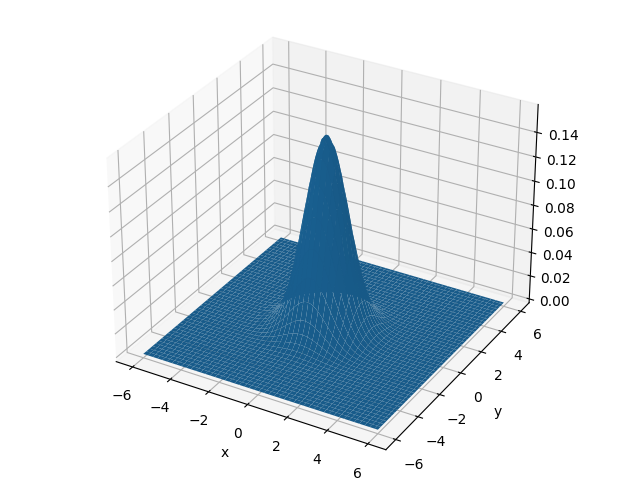
python代码如下:
from mpl_toolkits.mplot3d import Axes3D import numpy as np import matplotlib.pyplot as plt import math def dim2_gaussian_distribution(_x, _y, _mu1, _mu2, _sigma1, _sigma2, _rho): return np.exp((-1 / (2 * (1 - _rho ** 2))) * ( (_x - _mu1) ** 2 / (_sigma1 ** 2) - 2 * _rho * (_x - _mu1) * (_y - _mu2) / (_sigma1 * _sigma2) + (_y - _mu2) ** 2 / (_sigma2 ** 2) )) / (2 * np.pi * _sigma1 * _sigma2 * math.sqrt(1 - _rho ** 2)) def dim2_gaussian_show(_mu1=0, _mu2=0, _sigma1=1, _sigma2=1, _rho=0): fig = plt.figure() ax = Axes3D(fig) x = np.linspace(_mu1 - 6 * _sigma1, _mu1 + 6 * _sigma1, 1001) y = np.linspace(_mu2 - 6 * _sigma2, _mu2 + 6 * _sigma2, 1001) mesh_x, mesh_y = np.meshgrid(x, y) mesh_z = dim2_gaussian_distribution(mesh_x, mesh_y, _mu1, _mu2, _sigma1, _sigma2, _rho) plt.xlabel('x') plt.ylabel('y') ax.plot_surface(mesh_x, mesh_y, mesh_z) plt.show() if __name__ == '__main__': print("dim2_gaussian_distribution as main") dim2_gaussian_show()在多维情况下:
其中
为协方差矩阵,协方差的公式为: STL即Standard Template Library,标准模板库,常用的vector就是一个模板。
VS。
智能指针、lambda表达式等。到目前为止共有6个标准:C++98 C++11 C++14 C++17 C++20 C++23。
Ubuntu。
目录结构:
- /bin:二进制文件Binaries的缩写,存放最经常使用的命令。
- /boot:启动的核心文件。
- /dev:设备Device的缩写,存放外部设备。
- /etc:等等Etcetera的缩写,存放配置文件。
- /home:用户主目录。
- /lib:系统最基本的动态链接共享库。
- /opt:可选Optional的缩写,安装额外软件的目录。
- /proc:进程Process的缩写。
- /root:超级权限者用户主目录。
- /run:临时文件系统,存储系统启动以来的信息,重启即清除。
- /sbin:Superuser Binaries,超级权限者的系统管理程序。
- /srv:存放一些服务启动之后需要提取的数据。
- /sys:内核设备。
- /tmp:临时Temporary的缩写,存放临时文件。
- /usr:共享资源unix shared resources的缩写,类似windows的program files。
- /var:变量variable的缩写,存放不断扩充、修改的东西,如日志。
常用命令:
命令 含义 cat concatenate,在标准输出上列出文件的内容 cd change directory,切换当前工作目录,/表示根目录,~表示home,.表示当前目录,..表示上一级目录 chmod change mode。所有者、用户组、其他用户;读、写、执行 chown change owner,更改所有者 cp copy file,复制文件或目录 df disk free,磁盘使用情况统计 diff 逐行比较文件异同 du disk usage,显示目录或文件的大小 echo 将一些数据移到文件中 find 指定目录下查找文件 grep 查找文件里符合条件的字符串 head 查看文件的开头部分的内容 locate 搜索文件并打印位置 ls list files,列出当前工作目录包含的文件及子目录 man 查看某条命令的手册 mkdir make directory,创建目录 mv move file,对文件或目录移动或改名 pwd print work directory,打印当前工作目录的绝对路径 rm remove,删除文件或目录,无法恢复。-i:删除前逐一询问确认;-f:即使是只读文档,也直接删除,无需确认;-r:递归删除目录。rm -rf * / rm -rf .删除当前目录。 rmdir remove directory,删除空目录 sudo SuperUser Do,超级用户权限 tail 查看文件的末尾部分的内容 tar tape archive,归档多个文件到一个压缩包 touch 修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,则新建文件 Ubuntu安装软件的三种方式:
apt-get:
命令 含义 apt-get update 更新软件信息数据库 apt-get upgrade 进行软件升级 apt-get install xxx 安装xxx apt-get remove xxx 卸载xxx apt-get --purge remove xxx 卸载xxx,并删除配置文件 dpkg安装deb:
命令 含义 dpkg -i xxx.deb 安装xxx dpkg -r xxx 卸载xxx dpkg -P xxx (卸载xxx),并删除配置文件 dpkg -l 列出当前已安装的包 make install安装源码包:配置、编译、安装。
安装位置一般在/opt或/usr/bin下,具体可以通过which或whereis命令查找。which只能找到命令的位置,而whereis还可以找到命令的二进制文件,源文件和手动页文件。
只知道模糊的软件名称可以用apt search查找。
vim操作总结(文中“nu”代表阿拉伯数字):
NORMAL模式:
Vim中的操作符 含义 ESC 放弃正在输入的操作 h j k l 左 下 上 右 x 删除光标所在位置的字符 i 插入到光标所在位置之前 I 插入到本行第一个非空格字符之前 A 插入到本行最后一个非空格字符之后 o 在下一行新加一行并插入 O 在上一行新加一行并插入 u 删除上一次的改动(undo) U 删除一整行的改动 p 将最后一次删除的内容置入光标之后或下一行(针对dd) y 复制,亦可做操作符,比如yw / ye r 替换光标所在位置的字符 R 连续替换多个字符,每插入一个字符删除一个已有字符 w / nu-w 光标向前移动1 / N个单词(移动到词头) e / nu-e 光标向前移动1 / N个单词(移动到词尾)(如果当前光标不在词尾,本词也算一个) $ / nu-$ 光标向前移动1 / N行(移动到行尾)(本行也算) 0 移动光标到行 gg 跳转到文件第一行 G / nu-G 跳转到文章最后一行 / 跳转到第N行 / or ?-str 正或逆向查找字符串 n / N 顺或逆着当前方向查找,查尽后从头开始 % 查找配对括号()[]{} v 可视模式,选中内容进行后续操作,输入d删除,输入:+w+str存入文件 dw / d-nu-w 从当前光标位置开始(包括删除光标所在字符)删除一个单词,删除后光标停留在未删除的第一的字符上(英文会删除空格,中文删到出现英文字符或符号或数字或和英文遇到第一个空格删掉而结束) de / d-nu-e 比dw少删一个空格,删完光标在空格处 d$ / d-nu-$ 从当前光标删除到行末(包括当前字符,删除后光标在当前位置的前一个字符) dd / nu-dd 从当前行开始删除1 / N行(含本行) dw / de / d$ / dd(add nu)八个命令中d换成c 变删除为更改,即在删除之后进入INSERT模式 Ctrl-r redo Ctrl-g 显示当前编辑文件中当前光标所在行位置以及文件状态信息 Ctrl-o 回到之前的位置 Ctrl-i 去往较新的位置 Ctrl-w 切换窗口 COMMAND LINE模式:
Vim中的操作符 含义 ESC 放弃正在输入的命令 :+w(write) 保存 :+w+str 以字符串为名称保存 :+q(quit) 退出 :+q! 强制退出并保存 :+wq 保存并退出 :+x(=wq) 保存并退出 :+s/old/new 改变光标所在行的第一个匹配项 :+s/old/new/g 全行改变 :+#,#s/old/new/g 两个行号之间的匹配项改变 :+%s/old/new/g 全文改变 :+%s/old/new/gc 全文改变并对每个匹配项单独提示 :+! 外部shell命令,例如Linux下:!ls,:!rm和Windows下:!dir,:!del :+r+str 导入文件内容,:+r+!dir可以导入目录(均为插入到当前光标之后) :+set+hlsearch / nohlsearch 设置搜索高亮 :help(+something) 帮助文档或指令说明 :edit $VIM/_vimrc 编辑vimrc Ctrl-d 显示命令列表 TAB 命令补全 INSERT模式:
Vim中的操作符 含义 ESC 回到NORMAL模式
第2讲 认识SLAM
内容
经典视觉SLAM框架:
graph LR
A[传感器信息读取]==>B[前端视觉里程计]==>C[后端非线性优化]==>D[建图]
A-.->E[回环检测]-.->C
视觉里程计:Visual Odometry,VO。视觉里程计任务是估算相邻图像间相机的运动,以及局部地图的样子。VO又称为前端(Front End)。和计算机视觉联系紧密,如图像的特征提取和匹配。视觉里程计关心相邻图像之间的相机运动,和再往前的过去的信息没有关联,会不可避免地出现累计漂移。需要两种技术来校正这种漂移:后端优化和回环检测。
后端优化:Optimization。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在VO之后,又称为后端(Back End)。主要指处理SLAM过程中噪声的问题。
回环检测:Loop Closure Detection。回环检测判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。负责检测机器人回到原始位置的事件。
建图:Mapping。它根据估计的轨迹,建立与任务要求对应的地图。分为度量地图(Metric Map)和拓扑地图(Topological Map)。
SLAM问题是一个状态估计问题,已知运动测量的读数和传感器的读数(这两者都有噪声),求解定位问题和建图问题。按照运动和观测方程是否为线性,噪声是否服从高斯分布进行分类,分为线性/非线性和高斯/非高斯系统。线性高斯系统的无偏的最优估计可以由卡尔曼滤波器给出,非线性非高斯系统中采用扩展卡尔曼滤波器和非线性优化两大类方法。视觉SLAM发展历程:扩展卡尔曼滤波器->粒子滤波器等其他滤波器->以图优化为代表的优化技术。现在优化技术已经明显优于滤波器技术,只要计算资源允许,通常选择优化方法。
习题
文献下载工具推荐:sci-hub。
- 文献[1]:基于单目视觉的同时定位与地图构建方法综述。
- 文献[14]:基于图优化的同时定位与地图创建综述。
文献翻译工具推荐:copytranslator。
- 文献[9]:Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age。
- 文献[15]:Visual simultaneous localization and mapping: a survey。
- 文献[16]:Topological simultaneous localization and mapping: a survey。
- 文献[17]:Kalman Filter for Robot Vision: A Survey。
- 文献[18]:Recent advances in simultaneous localization and map-building using computer vision。
g++ name.cpp -o newname。
OK。
OK。
OK。
CMake Practice.pdf,广为流传,可以随时在网上找到。
TODO,参考CMake Practice.pdf可完成。
OK。
使用Clion。
使用Clion。
第3讲 三维空间刚体运动
内容
3.1 旋转矩阵
3.1.1 点和向量,坐标系
给定线性空间的一组基
向量点积:
向量叉积:定义为
3.1.2 坐标系间的欧式变换
欧式变换由旋转和平移组成。
同一个向量在不同单位正交基下的表示:
等式左右同时左乘
矩阵
旋转矩阵是一个行列式为1的正交矩阵。正交矩阵即逆为自身转置的矩阵,具有单位正交列向量,行列式等于+1或-1。
3.1.3 变换矩阵与齐次坐标
三维向量末尾添加1变成四维向量,称为齐次坐标。
矩阵
该矩阵的逆表示一个反向的变换:
3.2 实践:Eigen
3.3 旋转向量和欧拉角
3.3.1 旋转向量
任意旋转都可以用一个旋转轴和一个旋转角来刻画。因此可以用一个向量表示,其方向与旋转轴一致,而长度等于旋转角,这种向量称为旋转向量(或轴角/角轴,Axis-Angle)。假设旋转轴为一个单位长度的向量
符号^是向量到反对称矩阵的转换符,见3.1.1节。反之,我们也可以计算从一个旋转矩阵到旋转向量的转换,对于转角
因此:
对于转轴
因此转轴
3.3.2 欧拉角
使用三个分离的转角,把一个旋转分解成三次绕不同轴的旋转。欧拉角的一个重大缺点是会碰到著名的万向锁问题。用三个实数表达三维旋转都会不可避免地碰到奇异性问题。欧拉角不适用于插值和迭代,往往只用于人机交互中。
3.4 四元数
3.4.1 四元数的定义
复数:用复数集
类似的,在表达三维空间旋转时,也有一种类似于复数的代数:四元数。四元数是一种扩展的复数,既是紧凑的,也没有奇异性。
想要将复平面的向量旋转
一个四元数
其中,
也可以用一个标量和一个向量来表达四元数:
这里
在四元数中,乘以
3.4.2 四元数的运算
加法和减法
乘法
四元数的乘法是各项分别相乘再求和。
写成向量形式:
模长
共轭
逆
数乘
3.4.3 用四元数表示旋转
一个单位四元数
3.4.4 四元数到其他旋转表示的变换
四元数乘法也可以写成一种矩阵的乘法,设
得到四元数到旋转矩阵的转换:
对该式两边求迹解出:
3.5 相似、仿射、射影变换
除欧氏变换外三维空间还存在其他几种变换方式,欧氏变换
相似变换
相似变换比欧氏变换多了一个自由度,它允许物体进行均匀缩放,矩阵表示为:
旋转部分多了一个缩放因子
,三维相似变换的集合也叫做相似变换群,记作 。 仿射变换
仿射变换的矩阵形式如下:
仿射变换仅要求
是一个可逆矩阵,立方体经过仿射变换变成平行六面体。 射影变换
射影变换是最一般的变换,它的矩阵形式为:
为可逆矩阵, 为平移, 为缩放。 常见变换的性质比较(三维):
变换名称 矩阵形式 自由度 不变性质 欧氏变换 6 长度、夹角、体积 相似变换 7 形状 仿射变换 12 平行性、体积比 射影变换 15 接触平面的相交和相切
3.6 实践:Eigen几何模块
3.6.1 Eigen几何模块的数据演示
3.6.2 实际的坐标变换例子
3.7 可视化演示
3.7.1 显示运动轨迹
3.7.2 显示相机的位姿
习题
验证如下:
等式左右同时左乘
算出 等式左右同时左乘
算出 ,故 为正交矩阵。 推导并不复杂,利用旋转前的向量、旋转轴和旋转角表示出旋转后的向量也就得到了旋转矩阵。具体参考维基百科:罗德里格斯公式。
,由于 是虚四元数,所以 是虚四元数就等价于矩阵 的右上角分块(第1行的2~4列)为 ,代入计算后得到这部分为 ,所以 是虚四元数。 总结这四者间的转换关系图如下:
graph LR A(旋转矩阵) B(轴角) C(欧拉角) D(四元数) C-->|绕坐标轴的旋转矩阵的连乘|A-->|转角可由罗德里格斯公式取等式两边的迹得出,转轴是旋转矩阵特征值1对应的特征向量|B-->|式3_44的逆变换|D D-->|式3_44|B-->|罗德里格斯公式|A-->|一般情况由定义消元,常见类型的欧拉角容易查到公式|C A-->|较复杂,不展开|D D-->|式3_39|A实现代码如下:
#include <iostream> #include <Eigen/Core> using namespace std; using namespace Eigen; #define MATRIX_SIZE 9 int main(int argc, char **argv) { Matrix<double, MATRIX_SIZE, MATRIX_SIZE> matrix_NN = MatrixXd::Random(MATRIX_SIZE, MATRIX_SIZE); cout << "Origin Matrix:\n" << matrix_NN << endl; Matrix3d Matrix_33 = matrix_NN.block<3, 3>(0, 0); cout << "3x3 SubMatrix:\n" << Matrix_33 << endl; matrix_NN.block<3, 3>(0, 0) = Matrix3d::Identity(); cout << "Modified Matrix:\n" << matrix_NN << endl; return 0; }方法参见Eigen矩阵分解,主要有直接求逆、LU分解、QR分解、LLT分解、LDLT分解等,实现代码如下:
#include <iostream> #include <ctime> #include <Eigen/Core> #include <Eigen/Dense> using namespace std; using namespace Eigen; #define MATRIX_SIZE 10 int main(int argc, char **argv) { clock_t time_stt; Matrix<double, MATRIX_SIZE, 1> x; Matrix<double, MATRIX_SIZE, MATRIX_SIZE> A = MatrixXd::Random(MATRIX_SIZE, MATRIX_SIZE); A = A * A.transpose(); cout << "Matrix A:\n" << A << endl; Matrix<double, MATRIX_SIZE, 1> b = MatrixXd::Random(MATRIX_SIZE, 1); cout << "Vector b:\n" << b.transpose() << endl << endl << endl; time_stt = clock(); x = A.inverse() * b; cout << "time of normal inverse is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.partialPivLu().solve(b); cout << "time of PartialPivLU is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.fullPivLu().solve(b); cout << "time of FullPivLU is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.householderQr().solve(b); cout << "time of HouseholderQR is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.colPivHouseholderQr().solve(b); cout << "time of ColPivHouseholderQR is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.fullPivHouseholderQr().solve(b); cout << "time of FullPivHouseholderQR is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.completeOrthogonalDecomposition().solve(b); cout << "time of CompleteOrthogonalDecomposition is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.llt().solve(b); cout << "time of llt is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; time_stt = clock(); x = A.ldlt().solve(b); cout << "time of ldlt is " << 1000 * (clock() - time_stt) / (double) CLOCKS_PER_SEC << "ms" << endl; cout << "x = " << x.transpose() << endl; return 0; }
第4讲 李群与李代数基础
内容
4.1 李群李代数基础
像特殊正交群和特殊欧氏群这种只有一个(良好的)运算的集合称为群。
李群李代数的创始人:挪威数学家索菲斯·李(Sophus Lie)。
4.1.1 群
群是一种集合加上一种运算的代数结构。把集合记作
- 封闭性:
. - 结合律:
. - 幺元:
. - 逆:
.
李群是指具有连续(光滑)性质的群。
4.1.2 李代数的引出
在
4.1.3 李代数的定义
每个李群都有与之对应的李代数。李代数描述了李群的局部性质。李代数的定义如下:
李代数由一个集合
封闭性:
. 双线性:
. 自反性:
. 雅可比等价:
.
其中二元运算被称为李括号。例如三维向量上定义的叉积是一种李括号,
4.1.4 李代数
两个向量
由于三维向量与反对称矩阵一一对应,可以说
它与
4.1.5 李代数
把每个
李代数
4.2 指数与对数映射
4.2.1
任意矩阵的指数映射可以写成一个泰勒展开,其结果仍是一个矩阵:
同样地,对
定义
容易算出
化简该式可以得到:
结果和罗德里格斯公式形式完全一致。这说明
每个
4.2.2
其中:
总结
-so(3)&SE(3)-se(3).png)
4.3 李代数求导与扰动模型
4.3.1 BCH公式与近似形式
两个李代数指数映射乘积的完整形式,由Baker-Campbell-Hausdorff公式(BCH公式)。给出它展开式的前几项:
其中
假定对某个旋转
假定对某个李代数
对于
4.3.2
在位姿估计中经常会构建与位姿有关的函数,然后讨论该函数关于位姿的导数,以调整当前的估计值。而
- 用李代数表示姿态,然后对根据李代数加法来对李代数求导。
- 对李群左乘或右乘微小扰动,然后对该扰动求导,称为左扰动和右扰动模型。
第一种方式对应李代数的求导模型,而第二种则对应扰动模型。
4.3.3 李代数求导
假设对一个空间点
4.3.4 扰动模型(左乘)
设左扰动
4.3.5
假设某空间点
把最后的结果定义成一个算符
4.4 实践:Sophus
4.4.1 Sophus的基本使用方法
4.4.2 例子:评估轨迹的误差
4.5 相似变换群与李代数
在单目情况下一般会显式地把尺度因子表达出来,即对于空间点
相似变换关于矩阵乘法成群,称为相似变换群
4.6 小结
习题
验证成群即验证封闭性、结合律、幺元、逆这四条性质。
对于
而言: - 封闭性:
, 。 - 结合律:矩阵乘法都满足结合律,线性变换的描述问题,显然成立,参见3Blue1Brown。
- 幺元:
。 - 逆:
,故可逆。 ; ,故 , 。
对于
而言: 封闭性:
,故 。 结合律:同
。 幺元:
。 逆:
(分块矩阵行列式),故可逆。 , ,故 。
对于
而言: 封闭性:
,故 。 结合律:同
。 幺元:
。 逆:
,故可逆。 , ,故 。
- 封闭性:
验证构成李代数即验证封闭性、双线性、自反性、雅可比等价这四条性质。
封闭性:
。 双线性:
自反性:
雅可比等价:利用双重向量积公式:
: 封闭性:
, 是反对称矩阵,满足封闭性。 双线性:
同理:
。 自反性:
。 雅可比等价:
: 封闭性:
而
,故满足封闭性。 双线性:
同理:
。 自反性:
。 雅可比等价:
证明:
(4.20):
(4.21):
证明:
先叉乘后旋转和先旋转后叉乘是等价的。
证明:
证明:
: 设右扰动
对应的李代数为 ,对 求导: : 假设某空间点
经过一次变换 (对应李代数为 ),得到 。给 右乘一个扰动 ,设扰动项的李代数为 。
第5讲 相机与图像
内容
5.1 相机模型
相机将三维世界中的坐标点(单位为米)映射到二维图像平面(单位为像素)的过程能够用一个几何模型进行描述。相机的针孔模型和透镜的畸变模型描述了整个投影过程,这两个模型能够把外部的三维点投影到相机内部成像平面,构成了相机的内参数(Intrinsics)。
5.1.1 针孔相机模型
相机坐标系:
小孔成像模型:
相机自身软件处理后的模型:
像素坐标系(图像坐标系):在物理成像平面上固定着一个像素平面
令
其中,
一般把
记
相机前方
5.1.2 畸变模型
在针孔模型的基础上,为了获得好的成像效果,在相机的前方加透镜。透镜的加入对成像过程中光线的传播会产生新的影响::一是透镜自身的形状对光线传播的影响,二是在机械组装过程中,透镜和成像平面不完全平行导致光线穿过透镜投影到成像面时的位置发生变化。
由透镜形状引起的畸变称为径向畸变,分为两类:桶形畸变和枕形畸变。
由透镜和成像平面不平行引起的畸变称为切向畸变。
考虑归一化平面上的任意一点
5.1.3 双目相机模型
主流双目相机都是左右形式的,两个相机的光圈中心都在
5.1.4 RGB-D相机模型
RGB-D相机可以主动测量每个像素的深度,按原理可以分为两大类:
- 通过红外结构光(Structured Light)原理测量像素距离的。如Kinect 1代、Project Tango 1代、Intel RealSense等。
- 通过飞行时间(Time-of-flight, ToF)原理测量像素距离的。如Kinect 2代。
在红外结构光原理中,相机根据返回的结构光图案,计算物体离自身的距离;而在ToF原理中,相机向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体离自身的距离。
RGB-D相机可以根据生产时的各个相机摆放位置完成深度与彩色图像之间的配对,输出一一对应的彩色图和深度图。在同一图像位置可以同时读到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云。RGB-D即可以在图像层面处理,也可以在点云层面处理。
RGB-D相机的劣势:成本高、功耗大,红外光RGB-D相机易受日光或其他红外光干扰,因此不能在室外使用,同时用多个RGB-D相机如果不经调制也会互相干扰;无法测量透明材质物体的位置,因为接受不到反射光。
5.2 图像
5.3 实践:计算机中的图像
5.3.1 OpenCV的基本使用方法
5.3.2 图像去畸变
5.4 实践:3D视觉
5.4.1 双目视觉
5.4.2 RGB-D视觉
习题
首先安装ROS、下载并编译ROS的usb_cam包,运行usb_cam-test.launch,再在终端中运行:
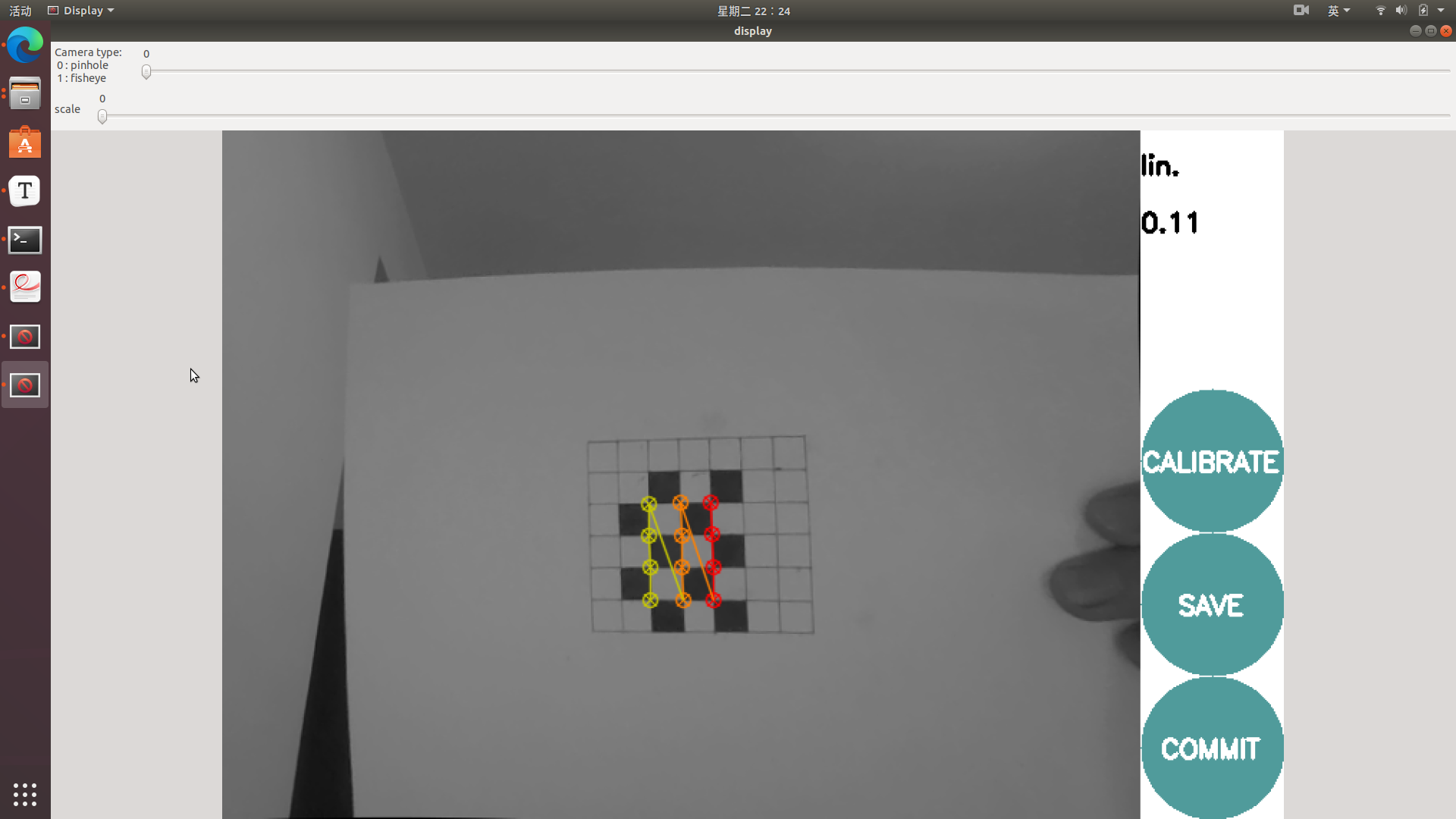
rosrun camera_calibration cameracalibrator.py --size 4x3 --square 0.01 image:=/usb_cam/image_raw camera:=/usb_camsize指标定板棋盘格内部角点个数,square指棋盘格单格边长,单位为m。
选用的棋盘格如下:

运行情况如下:
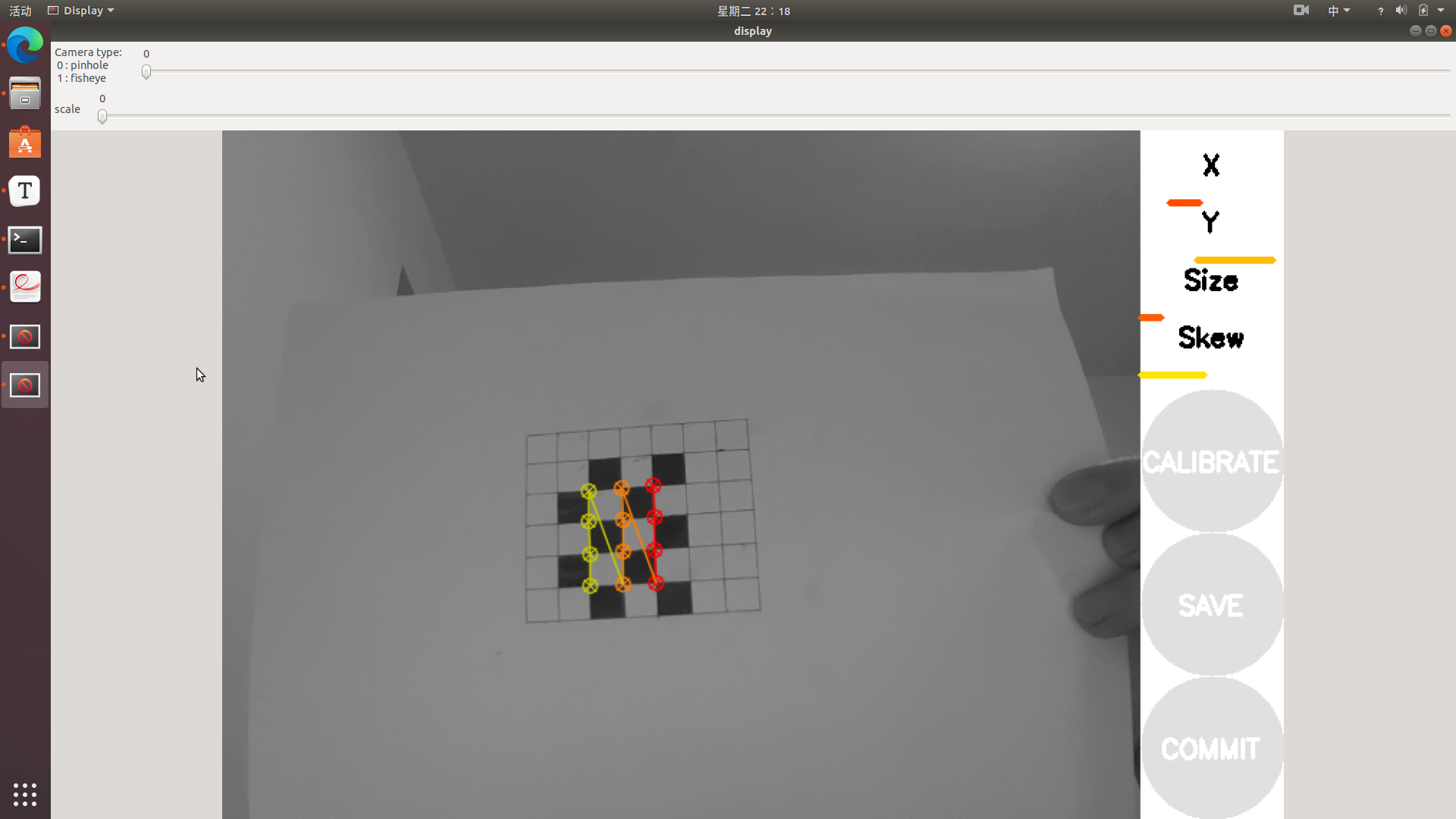
左右移动标定板使X进度条变绿,上下移动标定板使Y进度条变绿,前后移动标定板使Size进度条变绿,倾斜标定板使Skew进度条变绿。CALIBRATE按钮变绿后即可开始标定。
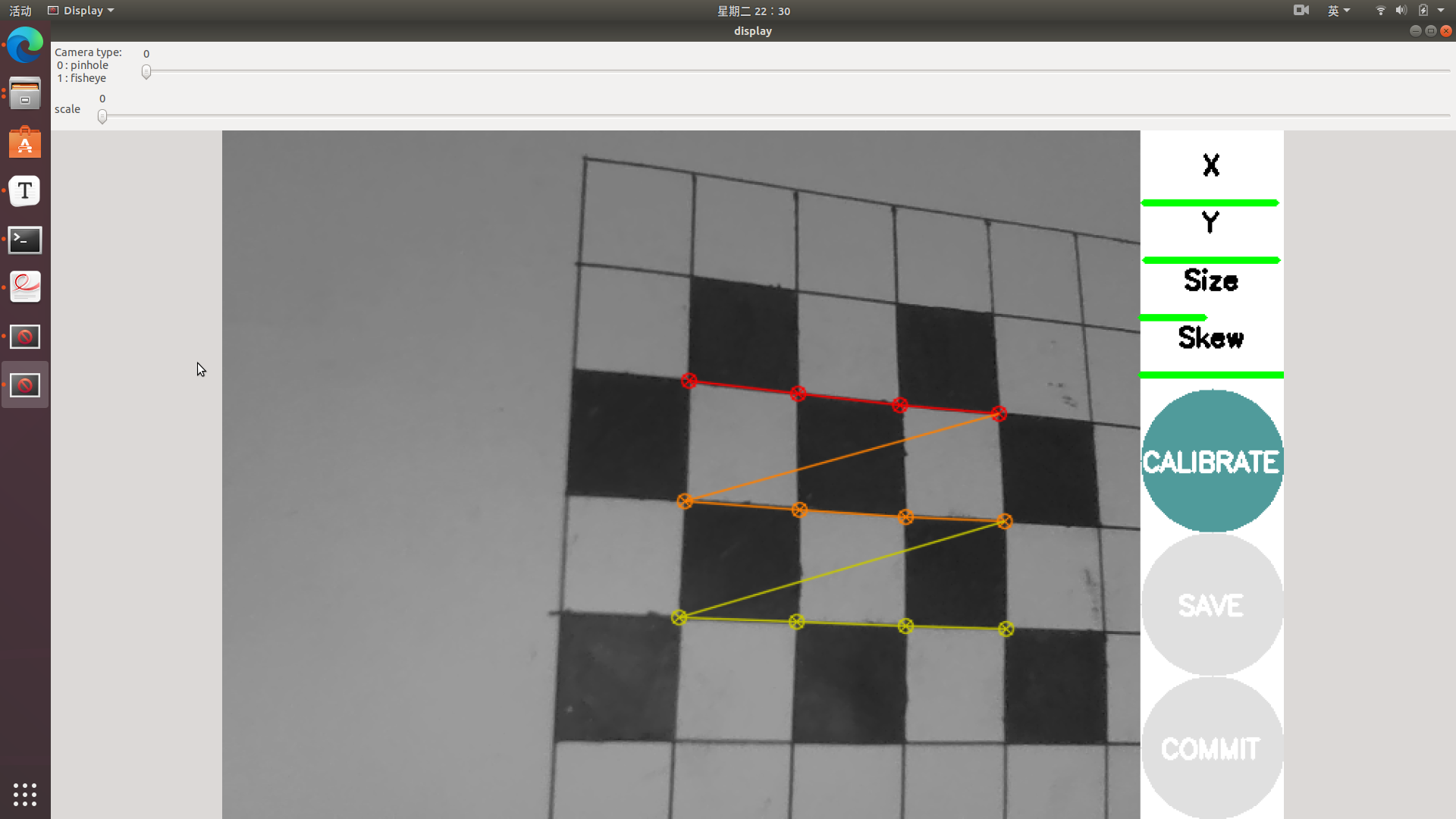
标定过程输出相机的内参矩阵、畸变参数、矫正矩阵和投影矩阵。
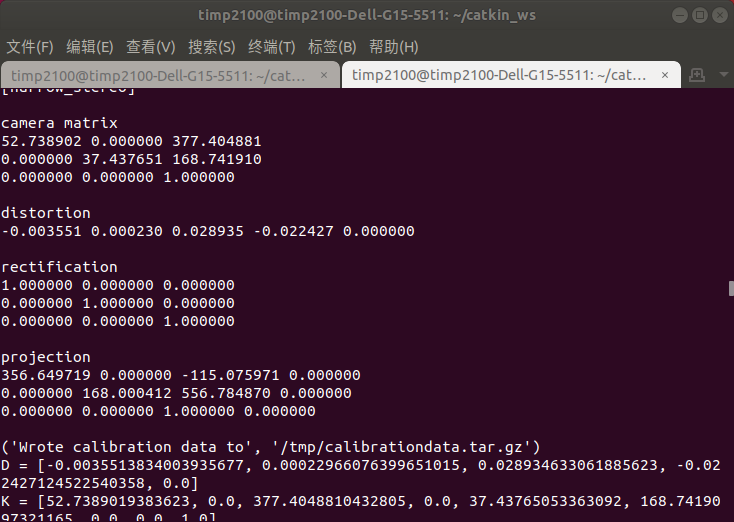
标定后可点SAVE按钮保存标定结果至/tmp/calibrationdata.tar.gz,点COMMIT按钮退出。
的物理意义是焦距长度在成像平面 方向换算成多少个像素, 的物理意义是成像平面上光心对应的点的像素坐标。分辨率变为2倍后成像平面单位长度上的像素变成两倍,所以 都变为两倍。 全局快门相机整幅场景在同一时间曝光,适合高速运动场景,但容易产生噪点;卷帘快门相机则是逐行曝光,可以达到更高的帧速,但高速运动场景易产生扭曲。
kinect2,需要标定:彩色相机和深度相机各自的内参矩阵、畸变参数,两种相机之间的位姿变换,深度图像中的深度值校准。
示例中是用行指针遍历的,其他方法:模板函数:
img.at<cv::Vec3b>(y,x)[c];迭代器:cv::MatConstIterator_<cv::Vec3b> Iterator_Now = img.begin<cv::Vec3b>(); cv::MatConstIterator_<cv::Vec3b> Iterator_End = img.end<cv::Vec3b>(); while(Iterator_Now != Iterator_End) { for(unsigned char c = 0; c < img.channels(); c++) { unsigned char data = (*Iterator_Now)[c]; } Iterator_Now++; }TODO。
第6讲 非线性优化
内容
6.1 状态估计问题
6.1.1 批量状态估计与最大后验估计
经典SLAM模型由一个运动方程和一个观测方程构成:
机器人的状态估计就是已知输入数据
贝叶斯法则:
利用贝叶斯法则,有:
最大似然估计:在什么样的状态下,最可能产生现在观测到的数据。
6.1.2 最小二乘的引出
对于某一次观测:
由于假设了噪声项
它依然是一个高斯分布,考虑单次观测的最大似然估计,可以使用最小化负对数来求一个高斯分布的最大似然。
由于仅有右端项与
该式等价于最小化噪声项(即误差)的一个二次型。这个二次型称为马哈拉诺比斯距离,又叫马氏距离。马氏距离可以看成由
通常假设不同时刻各个输入之间是独立的,各个观测之间是独立的,并且输入和观测也是独立的。可以对联合分布进行因式分解:
定义各次输入和观测数据与模型之间的误差:
最小化所有时刻估计值与真实读数之间的马氏距离,等价于求最大似然估计。负对数允许我们把乘积变成求和:
这样就得到了一个最小二乘问题。
6.1.3 例子:批量状态估计
6.2 非线性最二乘
6.2.1 一阶和二阶梯度法
在
如果做一阶泰勒展开(最速下降法):
如果做二阶泰勒展开(牛顿法):
6.2.2 高斯牛顿法
将
对该式求导并令导数为零,得到关于变量
称这个方程组为增量方程,将
高斯牛顿法的不足:为了求解增量方程,需要
6.2.3 列文伯格-马夸尔特方法
高斯牛顿法中采用的近似二阶泰勒展开(一阶泰勒展开平方)只能在展开点附近有较好的近似效果,可以给考虑增量限制一个范围(信赖区域)。
利用一个参数
即实际下降量与理论下降量的比值,如果
加上信赖域后单个步长的求解:
在列文伯格提出的优化方法中,
这是一个带不等式约束的优化问题,用拉格朗日乘子
其核心仍是计算增量的线性方程:
6.3 实践:曲线拟合问题
6.3.1 手写高斯牛顿法
6.3.2 使用Ceres进行曲线拟合
6.3.3 使用g2o进行曲线拟合
6.4 小结
习题
因为系数矩阵
超定,所以该线性方程组的方程数大于变量个数,即 列满秩且行数大于列数。 令该式的导数为0,即:
列满秩则 可逆。 其他常用优化库:NLopt、MATLAB Optimization Toolbox、CVX。
最速下降法 牛顿法 GN LM 算法简单,但过于贪心,容易走锯齿形路线,反而增加迭代次数 收敛快(具有二阶收敛速度),但海塞矩阵计算量大 用 近似海塞矩阵,简化了计算,但无法处理奇异或病态问题 使用信赖域算法解决高斯牛顿法的问题,但是收敛速度下降了 ,如果 中含有零分量,则不正定,此时几何上函数在该点附近时平坦的,无法找到下一次迭代的下降方向,所以这种情况下解不稳定。 LM法通过拉格朗日乘子将最速下降法和高斯牛顿法结合,而DogLeg法通过信赖域将最速下降法和高斯牛顿法结合。
DogLeg法:
- 如果高斯牛顿法的解在信赖域内,则采用高斯牛顿法;
- 如果高斯牛顿法和最速下降法的解都不在信赖域内,则采用最速下降法并将步长缩短到信赖域半径;
- 如果高斯牛顿法的解不在信赖域内但最速下降法的解在信赖域内,则用两个向量求和得到步长的方向,步长的大小为信赖域半径。
TODO。
TODO。
OK。
第7讲 视觉里程计1
内容
7.1 特征点法
SLAM前端也叫视觉里程计,视觉里程计算法主要分为两大类:特征点法和直接法,特征点法是目前的主流。
7.1.1 特征点
特征点是图像里一些特别的地方,如角点、边缘和区块,其中角点最容易检测,角点提取算法如Harris角点,FAST角点,GFTT角点等。
实际应用中角点往往不能满足我们对特征点的要求,还需要用到更加稳定的局部图像特征,如SIFT、SURF、ORB等。
特征点的性质:
- 可重复性:相同的特征可以在不同的图像中找到。
- 可区别性:不同的特征有不同的表达。
- 高效率:图像中特征点数量远小于像素的数量。
- 本地性:特征点仅与一小片图像区域相关。
特征点由关键点和描述子两部分组成。
7.1.2 ORB特征
ORB是一种典型的实时图像特征点,由Oriented FAST关键点(一种改进的FAST角点)和BRIEF描述子组成。FAST角点检测是将与领域像素灰度差别大的像素视为角点。
7.1.3 特征匹配
暴力匹配:测量两幅图像特征点对的描述子的距离(描述了特征的相似程度),对于BRIEF这样的二进制描述子,可采用汉明距离(两个二进制串的不同位的个数)度量。
快速近似最近邻:FLANN,解决特征点数量很大时暴力匹配法运算量太大的问题。
7.2 实践:特征提取和匹配
7.2.1 Opencv的ORB特征
7.2.2 手写ORB特征
7.2.3 计算相机运动
- 单目相机仅知道2D的像素坐标,根据两组2D点估计相机运动,用对极几何解决。
- 双目或RGB-D相机是根据两组3D点估计相机运动,用ICP解决。
- 一组3D点和一组2D点的情况用PnP解决。
7.3 2D-2D:对极几何
7.3.1 对极约束
7.3.2 本质矩阵
如考虑平移和旋转各有3个自由度,共有6个自由度,根据尺度等价性去掉一个自由度,可用五点法求解,但用到了本质矩阵的内在性质:奇异值为
如果只考虑尺度等价性可用八点法求解,但求出的本质矩阵不一定满足内在性质,设对得到的
7.3.3 单应矩阵
如果特征点都落在同一平面(墙、地面等),则可以通过单应性进行运动估计。特征点共面或者相机发生纯旋转时,基础矩阵的自由度下降,即退化现象,为避免退化带来的影响,可以同时估计基础矩阵和单应矩阵,选择重投影误差小的作为最终结果。
7.4 实践:对极约束求解相机运动
单目SLAM的初始化是不可避免的,初始化的两张图片必须有一定程度的平移(消除尺度不确定性);匹配的特征点多于8对时可以求最小二乘解,当可能存在误匹配的情况下,用随机采样一致性来求更好。
随机采样一致性是从一组包含异常值的观测数据中,估计数学模型的参数;此时异常值对估计值无影响,也可以说它是一种异常值检测方法。
7.5 三角测量
用相机的运动估计特征点的空间位置,单目相机无法通过一张图像获得像素的深度信息,需要通过三角测量(三角化)的方法估计深度。
7.6 实践:三角测量
7.6.1 三角测量代码
7.6.2 讨论
7.7 3D-2D:PnP
如果两张图像中的一张特征点的3D位置已知,另一张特征点的2D位置已知,则至少只需3个点对(以及至少一个额外点验证结果)即可估计相机运动。
PnP(Perspective-n-Point)问题有很多种求解方法,如P3P、DLT(直接线性变换)、EPnP、UPnP等;也可以用非线性优化方法构建最小二乘问题迭代求解,即光束法平差(Bundle Adjustment,BA)。
7.7.1 直接线性变换
未知量
7.7.2 P3P
利用三角形相似关系求解相机位姿的一种方法,求解方便,但存在以下问题:利用的信息有限,给定的匹配点数多于3时,无法有效利用更多信息;如果给定的匹配点受噪声影响或存在误匹配,则算法失效。
改进方法:EPnP、UPnP等。
SLAM中常用P3P/EPnP等方法估计相机位姿(得到初始值),再进行BA非线性优化,在相机运动足够连续时,也可以假设相机不动或匀速运动,用推测值作为初始值进行优化。
7.7.3 最小化重投影误差求解PnP
重投影误差:将3D点的投影位置与观测位置作差;这和相机位姿、空间点位置都有关。最小化重投影误差将得到一个最小二乘问题,这种把相机和三维点放在一起(都视为优化变量)进行最小化的问题,统称为Bundle Adjustment。
7.8 实践:求解PnP
7.8.1 使用EPnP求解位姿
7.8.2 手写位姿估计
7.8.3 使用g2o进行BA优化
7.9 3D-3D:ICP
已有一组匹配好的3D点:
这个问题可以用迭代最近点(Iterative Closest Point,ICP)求解。
7.9.1 SVD方法
构建关于误差的最小二乘问题,利用SVD分解可以求出
7.9.2 非线性优化方法
用非线性优化方法解关于误差的最小二乘问题,ICP问题存在唯一解或无穷多解的情况。在唯一解的情况下,只要能找到极小值解,这个极小值就是全局最优解。
匹配已知的情况下,这个最小二乘问题有解析解,所以没有必要进行迭代优化;基于优化的ICP的应用场景一般为在某些场合下(如RGB-D SLAM)中,一个像素的深度数据可能有,也可能没有,此时可以混合使用PnP和ICP优化,对已知深度的点建模3D-3D误差,对未知深度的点建模3D-2D的重投影误差,将所有误差放在同一个问题中考虑,可使求解更加方便。
7.10 实践:求解ICP
7.10.1 实践:SVD方法
7.10.2 实践:非线性优化方法
7.11 小结
本章内容:
- 特征点的提取与匹配。
- 2D-2D特征点匹配估计相机运动、估计空间点位置。
- 3D-2D的PnP问题,3D-3D的ICP问题,线性解法和BA解法。
习题
其他特征点如SIFT、SURF。
SIFT(Scale-Invariant Feature Transform)即尺度不变特征变换。经由尺度空间的极值检测、关键点定位、方向定位、计算关键点描述子来确定特征点。
SURF(Speeded Up Robust Features)即加速鲁棒特征,是SIFT的改进,比SIFT更加高效。
三者对比:
- 计算速度:ORB>>SURF>>SIFT
- 鲁棒性:SIFT
SURF>ORB
将
ORB::create改为对应的特征点即可。使用GFTT特征点。GFTT即goodFeaturesToTrack。
FLANN(Fast Library for Approximate Nearest Neighbors)即快速近似最近邻库,通过k-d树、k-means等方法跳过不必要的匹配来实现加速。匹配加速算法多用于SIFT特征点,如VF-SIFT(very fast SIFT);也可以硬件加速,比如采用GPU/FPGA。
参考OpenCV求解PnP。
TODO。
TODO。
会导致计算出的
与实际值偏差大,使用RANSAC避免。 TODO。
TODO。
第8讲 视觉里程计2
内容
8.1 直接法的引出
特征点法有如下不足:
- 关键点提取和描述子计算耗时。
- 忽略了除特征点外大量可能有用的信息。
- 相机运动到特征点缺失的地方可能由于特征点不足而导致算法失效。
可使用光流法(Optical Flow)/直接法(Direct Method)克服这些缺点。
8.2 2D光流
光流是一种描述像素随时间在图像之间运动的方法。计算部分像素运动的称为稀疏光流(如Lucas-Kanade光流),计算所有像素运动的称为稠密光流(如Horn-Schunck光流)。
LK(Lucas-Kanade)光流,将图像看作时间的函数
8.3 实践:LK光流
8.3.1 使用LK光流
8.3.2 用高斯牛顿法实现光流
最小化灰度误差估计的最优的像素偏移。
有单层光流和多层光流之分,当相机运动较快,两张图像之间差异较大时,初始值距最优值较远,容易陷入局部极小值;可以通过建立图像金字塔,由粗至精(Coarse-to-fine)作多层光流,每一层的优化结果为下一层的初始值,可较好地克服该问题。
8.3.3 光流实践小结
光流法可以加速基于特征点的视觉里程计算法,避免计算和匹配 描述子的过程,但要求相机运动较平滑(或采集频率较高)。
8.4 直接法
8.4.1 直接法的推导
直接法同样基于灰度不变假设,不需要特征点,完全通过优化方法估计相机运动,最小化光度误差。
8.4.2 直接法的讨论
根据空间点的来源将直接法分类:
- 稀疏直接法:空间点来自于稀疏关键点,速度最快,但只能计算稀疏的重构。
- 半稠密(Semi-Dense)直接法:由于像素梯度为0时,雅可比为0,对增量计算无贡献,故选择像素梯度明显的地方,可以重构半稠密结构。
- 稠密直接法,计算所有像素,重构稠密结构;通常CPU做不到实时计算,需要GPU加速。
8.5 实践:直接法
8.5.1 单层直接法
8.5.2 多层直接法
8.5.3 结果讨论
当图像强烈非凸时,直接法容易陷入局部极小值。
8.5.4 直接法优缺点总结
优点:省去特征点和描述子的计算时间;只要求有像素梯度,不要求有特征点;可构建(半)稠密地图。
缺点:图像通常具有强非凸性;灰度值不变的强假设;单个像素没有区分度,需要大量的点。
习题
- 稀疏光流:LK、KLT;稠密光流:HS、Farneback。
- 未考虑深度,不能很好地反映梯度,可以用一个和深度成反比的系数代替1。
- 可以,但不及反向光流法合适,因为直接法没有用特征点,完全依靠优化算法,梯度的精度会带来更大的影响。
- TODO。
- TODO。
第9讲 后端1
内容
9.1 概述
9.1.1 状态估计中的概率解释
贝叶斯法则:
马尔可夫性质:当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态,称这个随机过程具有马尔可夫性质。
假设马尔可夫性的条件下,得到以扩展卡尔曼滤波为代表的滤波器方法,否则得到非线性优化方法。
9.1.2 线性系统和KF
9.1.3 非线性系统和EKF
9.1.4 EKF的讨论
EKF的局限性:
- 假设了马尔可夫性。
- 非线性误差。
- 需要存储协方差矩阵,在大型场景中数据过于庞大。
- 没有异常检测机制。
在同等计算量的情况下,非线性优化的精度和鲁棒性都更好。
9.2 BA与图优化
9.2.1 投影模型和BA代价函数
9.2.2 BA的求解
9.2.3 稀疏性和边缘化
目标函数的
9.2.4 鲁棒核函数
在BA问题中,将最小化误差项的二范数平方和作为目标函数,如果某个误差项给的数据是错误的,可能由于该项梯度大而导致优化主要倾向于使该项的误差减小,优化向不正确的方向进行。
出现这种问题的原因是,当误差很大时,二范数增长得太快。使用鲁棒核函数(Robust Kernel)可有效避免这种问题,鲁棒核函数把二范数平方替换成一个增长没有那么快的函数,同时保证光滑性,常见的鲁棒核函数:Huber核、Cauchy核、Tukey核。
9.3 实践:Ceres BA
9.3.1 BAL数据集
9.3.2 Ceres BA的书写
9.4 实践:g2o求解BA
9.5 小结
习题
由9.16:
, 9.17:
得: 由SMW公式:
令
,代入SMW公式可证。 g2o和Ceres使用的目标函数不同,g2o的目标函数是Ceres的两倍。
不采用Ceres的自动消元效果会下降。
证明:
显然半正定, ,令 , 令
,则 故
半正定, 半正定。 TODO。
TODO。
第10讲 后端2
内容
10.1 滑动窗口滤波和优化
10.1.1 实际环境下的BA结构
由于算力有限,必须控制后端的计算规模,常用的方法:抽取关键帧,滑动窗口法、建立共视图、位姿图等。
10.1.2 滑动窗口法
仅保留离当前时刻最近的N个关键帧(或按照某种原则,取时间上靠近,空间上又可以展开的关键帧)。
10.2 位姿图
10.2.1 位姿图的意义
特征点的数量是远多于位姿点的,如果仅优化位姿,不优化特征点,则计算量会大大减小,这样只保留了关键帧的轨迹,从而构建了位姿图(Pose Graph)。
10.2.2 位姿图的优化
10.3 实践:位姿图优化
10.3.1 g2o原生位姿图
10.3.2 李代数上的位姿图优化
10.3.3 小结
习题
TODO(1~5)。
第11讲 回环检测
内容
11.1 概述
11.1.1 回环检测的意义
SLAM的过程中会产生累计误差,导致无法构建全局一致的地图,回环检测可以解决这一问题,明显提升SLAM系统的精度与稳健性;回环检测还可以用于重定位。
11.1.2 回环检测的方法
简单朴素的方式:任意两幅图像都做特征匹配或随机抽取之前的几帧与当前帧做比较,这两种方法都有问题,前者计算量太大,后者容易漏检。合理的方法应该至少有一个在哪里可能出现回环的预计,有两种思路:一是基于里程计的几何关系(由于累计误差的存在,这周思路不太可靠),另一个是基于外观的几何关系(当前主流)。
11.1.3 准确率和召回率
根据事实与检测结果分为真阳性(TP)、假阳性(FP)(又称为感知偏差)、假阴性(FN)(又称为感知变异)和真阴性(TN);希望TP和TN大,FP和FN小。
准确率:Precision=TP/(TP+FP)。
召回率:Recall=TP/(TP+FN)。
通常的P值(Precision)和R值(Recall)是一对矛盾,SLAM对准确率的要求更高,对召回率相对宽容,因为错误的回环检测会导致非常严重的偏差,一般在SLAM的回环检测中会将参数设置得更严格,并在检测后加上回环验证。
11.2 词袋模型
词袋,即Bag-of-Words(BoW),目的是用“图像上有哪几种特征”来描述一幅图像,词袋模型有如下步骤:
- 选取单词(Word),构成字典(Dictionary)。
- 确定一幅图像中出现了哪些单词(仅关心是否出现,不关心顺序),从而把一幅图像转化为一个向量。
- 比较两幅图像对应向量的相似程度。
11.3 字典
11.3.1 字典的结构
单词与特征点不同,不是从单幅图像上提取出来的,而是某一类特征的组合,字典的生成类似于一个聚类(Clustering)问题。
聚类问题常见于无监督学习(Unsupervised ML)中,用于让机器自行寻找数据中的规律。
例如利用N个特征点生成一个有k个单词的字典,可用经典的K均值(K-means)算法解决,算法步骤:
- 随机选取k个中心点。
- 对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类。
- 重新计算每个类的中心点。
- 如果每个中心点都变化很小,则算法收敛,退出;否则返回第2步。
建立字典后需要查找匹配,字典一般规模较大,直接查找运算量太大,如果用一定的数据结构来表达可以加速查找,例如k叉树。若有N个特征点,要建立深度为d、分叉为k的树,步骤如下:
- 在根节点,使用K-means将样本聚为k类。
- 对于第一层的节点,将属于该节点的样本聚为k类得到下一层。
- 依次类推,直到得到叶子层,叶子节点就是单词(Word)。
11.3.2 实践:创建字典
11.4 相似度计算
11.4.1 理论部分
表达相似度时,不同的单词应该有不同的权值,常用权值:TF-IDF(Term Frequency–Inverse Document Frequency),即:频率−逆文档频率。某单词在一幅图像中经常出现,它的区分度就高;某单词在字典中出现的频率越低,分类图像时区分度越高。
建立字典时计算IDF:设所有单词数量为
11.4.2 实践:相似度的计算
11.5 实验分析与评述
11.5.1 增加字典规模
增加字典规模后所有图像之间的相似度都减小,但相关图像的相似度与无关图像相比更加显著了。
11.5.2 相似性评分的处理
不同场景的相似度参照值不同,比如办公室不同位置的相似度也很高,可取一先验相似度(某时刻关键帧图像与上一时刻的关键帧的相似性)作为参照值以适应不同的环境,如果当前帧与之前某关键帧的相似度超过当前帧与上一个关键帧相似度的3倍,就认为可能存在回环。
11.5.3 关键帧的处理
用于回环检测的关键帧应较为稀疏,以避免临近帧匹配为回环;将相近的回环聚为一类以避免反复计算。
11.5.4 检测之后的验证
回环验证,时间上的一致性检测:认为单次检测到的回环并不足以构成良好的约束,而在一段时间中一直检测到的回环,才是正确的回环;空间上的一致性:对回环检测到的两个帧进行特征匹配,估计相机的运动,代入位姿图中看是否有很大的出入。
11.5.5 与机器学习的关系
词袋模型本身是一个非监督的机器学习过程,利用机器学习改进回环检测:使用机器学习的图像特征代替ORB等人工设计的特征?比K-means+树结构更好的聚类方法?
习题
- 选择不同的相似度阈值,分别按定义计算P值(Precision)和R值(Recall),再调用plot函数画图像即可。
- TODO。
- TODO。
- 欧氏距离、曼哈顿距离
、切比雪夫距离 、汉明距离等。 - 参考Chow-Liu Tree。
- 随机蕨法、基于深度学习的方法。
第12讲 建图
内容
12.1 概述
从视觉SLAM的角度看,建图是服务于定位的,而在应用层中,建图往往还有其他需求,归纳建图的应用如下:
- 定位。定位是地图的一项基本功能,保存地图后也可以进行重定位,用稀疏路标地图即可完成。
- 导航。导航是指机器人能够在地图中进行路径规划,在任意两个地图点间寻找路径,然后控制自己运动到目标点的过程。导航至少需要知道地图中哪些地方不可通过,而哪些地方是可以通过的,这就需要稠密的地图。
- 避障。与导航类似,但更注重局部的、动态的障碍物的处理,同样需要稠密的地图。
- 重建。需要稠密的地图,重建周围环境,对外观有一定要求。
- 交互。机器人与人、与地图、人与地图之间的互动,需要机器人对地图有更高层面的认知,也称为语义地图。
12.2 单目稠密重建
12.2.1 立体视觉
相机测量物体深度有如下方法:
- 单目相机,三角化。
- 双目相机,利用视差计算。
- RGB-D相机,直接获取。
前两种称为立体视觉(Stereo Vision),其中移动单目相机又称移动视角的立体视觉(Moving View Stereo,MVS)。
稠密建图中的匹配技术:极线搜索和块匹配技术;深度值误差的缩小、值的收敛:深度滤波器技术。
12.2.2 极线搜索和块匹配
已知某一相机观测到了某个像素
计算像素块之间差异的方法:
SAD(Sum of Absolute Difference):
SSD(Sum of Squared Distance):
NCC(Normalized Cross Correlation),归一化互相关:
在实际工程中可以先做去均值处理,以在一定程度上消除亮度整体变化的影响。
沿着极线上的相似度往往是一个非凸函数,由多个峰值,在这种情况下,我们会倾向于使用概率分布描述深度值(深度滤波器),而非用某个单一的数值来描述深度。
12.2.3 高斯分布的深度滤波器
对像素点深度的估计,本身也可建模为一个状态估计问题,有滤波器和非线性优化两种求解思路,虽然非线性优化效果更好,但SLAM中为了使计算量更少,实时性更强,往往在深度估计中会采用滤波器方法。
估计稠密深度的步骤:
- 假设所有像素的深度满足某个初始的高斯分布。
- 有新数据产生时,通过极线搜索和块匹配确定投影点位置。
- 根据几何关系计算三角化后的深度及不确定性。
- 将当前观测融合进上一次的估计中。若收敛则停止计算,否则返回第2步。
12.3 实践:单目稠密重建
12.3.1 实验分析与讨论
12.3.2 像素梯度的问题
梯度不明显的像素在块匹配时没有区分性,难以有效地估计其深度,这反映了立体视觉中一个常见的问题:对物体纹理的依赖性。如果像素梯度垂直于极线方向,做块匹配时,会发现匹配程度都是一样的,因此得不到有效的匹配。
12.3.3 逆深度
实际中深度值的分布形状不太符合高斯分布,它的尾部可能稍长,负数区域为零;在一些室外应用中,可能存在距离非常远,乃至无穷远处的点,用高斯分布描述它们会有一些数值计算上的困难。在工程实践中,假设深度的倒数,也就是逆深度,为高斯分布是比较有效的。
12.3.4 图像间的变换
在块匹配之前,做一次图像到图像间的变换是一种常见的预处理方式,即把参考帧与当前帧之间的相机运动考虑进来。
12.3.5 并行化:效率的问题
稠密深度图的估计计算量庞大,非常费时,但各像素点的深度估计是彼此无关的,可以使用并行化加速。
12.3.6 其他的改进
处理误匹配、外点、深度突变等。
12.4 RGB-D稠密建图
RGB-D相机容易获得可靠的深度信息,通过对三维点的拼接构造点云地图(Point Cloud Map),进一步可以使用三角网格(Mesh)、面片(Surfel)估计物体的表面,通过体素(Voxel)建立占据网格地图(Occupancy Map)。
RGB-D建图的基本原理:假设在RGB-D图像中观测到某个像素带有深度
12.4.1 实践:点云地图
在实践中常采用的额外措施:去掉深度无效的点,用统计滤波器方法去除孤立点(与其它点距离均值较大的点,目的是去除噪声点),用体素网络滤波器进行降采样(消除由于视野重叠问题导致的密集重复点,保证在一定大小的立方体(或称体素)内仅有一个点)。
点云地图有许多不足,如无法表示任意空间点是否被占据,因而不能满足导航与避障的需求;只含有离散的点,不符合可视化的习惯。通常会以点云地图为基础加工出其它的地图。
12.4.2 从点云重建网络
大致思路是先计算点云的法线,再从法线计算网格。经典的重建算法:Moving Least Square、Greedy Projection。
12.4.3 八叉树地图
点云地图需要大量的存储空间,且无法处理运动物体,八叉树地图可以解决这两个问题。
八叉树地图每一层将一个小方块分成同样大小的八个,不断向下分层,直到最小的方块大小达到建模的最高精度。
当某个方块的所有子节点都被占据或都不被占据时,就没必要展开这个节点,这使得八叉树地图更省空间。
由于噪声的影响,某个点观测到的占据状态可能是实时变化的,还有可能其占据状态是未知的;为了更好地处理这些情况,可以用概率形式表达某节点是否被占据的事情,设定一初始的概率值,如果不断观测到它被占据,那么让这个值不断增加;反之,如果不断观测到它是空白,那就让它不断减小即可。这也使得八叉树地图可以实现动态建模。
如果让概率值不断增加或减小,可能会出现概率值不在
12.4.4 实践:八叉树地图
12.5 TSDF地图和Fusion系列
实时三维重建是一个与SLAM非常相似但又有稍许不同的研究方向,SLAM以定位为主体,而实时三维重建以建图为主体。Fusion系列是一系列利用RGB-D图像进行实时三维重建的方法,TSDF是Truncated Signed Distance Function,截断符号距离函数。
12.6 小结
习题
推导:
化简
: 故:
因此:
TODO。
TODO。
全局路径规划:Dijkstra、A*、D*;局部路径规划:人工势场法等。
TODO。
TODO。
第13讲 实践:设计SLAM系统
内容
13.1 为什么要单独列工程章节
13.2 工程框架
处理的最基本单元是图像,在双目视觉里那就是一对图像,称为一帧,对帧提取特征(2D点),计算特征的3D位置,即为路标。
13.3 实现
13.3.1 实现基本数据结构
Frame、Feature、MapPoint、Map。
13.3.2 前端
13.3.3 后端
13.4 实验效果
习题
TODO(1~3)。
第14讲 SLAM:现在与未来
内容
14.1 当前的开源方案
常见的开源SLAM方案:
| 方案名称 | 传感器形式 | 地址 |
|---|---|---|
| MonoSLAM | 单目 | https://github.com/hanmekim/SceneLib2 |
| PTAM | 单目 | https://www.robots.ox.ac.uk/~gk/PTAM/ |
| ORB-SLAM | 单目为主 | http://webdiis.unizar.es/~raulmur/orbslam/ |
| LSD-SLAM | 单目为主 | https://vision.in.tum.de/research/vslam/lsdslam |
| SVO | 单目 | https://github.com/uzh-rpg/rpg_svo |
| DTAM | RGB-D | https://github.com/anuranbaka/OpenDTAM |
| DVO | RGB-D | https://github.com/tum-vision/dvo_slam |
| DSO | 单目 | https://github.com/JakobEngel/dso |
| VINS系列 | 单目+IMU为主 | https://github.com/HKUST-Aerial-Robotics/VINS-Mono |
| RTAB-MAP | 双目/RGB-D | https://github.com/introlab/rtabmap |
| RGBD-SLAM-V2 | RGB-D | https://github.com/felixendres/rgbdslam_v2 |
| Elastic Fusion | RGB-D | https://github.com/mp3guy/ElasticFusion |
| Hector SLAM | 激光 | http://wiki.ros.org/hector_slam |
| GMapping | 激光 | http://wiki.ros.org/gmapping |
| OKVIS | 多目+IMU | https://github.com/ethz-asl/okvis |
| ROVIO | 单目+IMU | https://github.com/ethz-asl/rovio |
14.1.1 MonoSLAM
2007,第一个实时的单目视觉SLAM系统,基于特征点、EKF。
14.1.2 PTAM
2007,Parallel Tracking and Mapping,提出并实现了跟踪与建图过程的并行化,开启前后端的时代,第一个使用非线性优化方案,结合AR。
14.1.3 ORB-SLAM
2015,PTAM继承者,主流的特征点 SLAM的一个高峰,完善、易用。支持单目、双目、RGB-D三种模式,整个系统围绕ORB特征进行计算,回环检测,三线程:前端、小图、大图,围绕特征点的优化。
14.1.4 LSD-SLAM
2014,Large Scale Direct monocular SLAM,直接法、半稠密单目SLAM。
14.1.5 SVO
2014,Semi-direct Visual Odoemtry,半直接法,深度滤波器(均匀-高斯混合分布),轻量级,无人机(不适合平视相机),只是一个视觉里程计,没有后端优化和回环检测。
14.1.6 RTAB-MAP
2013,Real Time Appearance-Based Mapping,RGB-D SLAM,基于特征的视觉里程计、基于词袋的回环检测、后端的位姿图优化,以及点云和三角网格地图。完善、庞大、集成度高、不易二次开发,更适合应用而非研究。
14.1.7 其他
14.2 未来的SLAM话题
两类发展趋势:一类是轻量级、小型化;另一类是精密的三维重建、场景理解(需要高算力)。
14.2.1 视觉+惯性导航SLAM
IMU与视觉互补:
- 运动过快时相机会出现运动模糊或两帧之间重叠区 域太少以至于无法进行特征匹配,但IMU善于估计于短时间内的快速运动。
- 长时间范围内IMU数据会出现漂移,但相机数据基本不会有漂移,慢速运动时可以用相机数据有效地估计并修正IMU读数中的漂移。
- 当图像发生变化时,视觉本质上无法知道是环境改变了还是自身运动了,结合IMU可以某种程度上减轻动态物体的影响。
两者结合的产物:VIO(Visual Inertial Odometry),视觉惯性里程计。分为两大类:松耦合与紧耦合,松耦合是指IMU和相机分别进行自身的运动估计,然后对其位姿估计结果进行融合。紧耦合是指把IMU的状态与相机的状态合并在一起,共同构建运动方程和观测方程,然后进行状态估计。
14.2.2 语义SLAM
和深度学习技术结合,语义可以帮助SLAM给图片带上物体标签,也可用于回环检测、BA;SLAM可以帮助训练物体识别和分割。
14.2.3 SLAM的未来
基于线/面特征的 SLAM、基于线/面特征的SLAM、多机器人的SLAM等。
习题
TODO(1~2)。